數(shù)組簡(jiǎn)介
如果各位猿友是一路跟著LZ看到這里的,那么數(shù)組的定義就非常簡(jiǎn)單了,它就是一個(gè)相同數(shù)據(jù)類型的數(shù)據(jù)集合。數(shù)組存儲(chǔ)在一系列邏輯上連續(xù)的內(nèi)存塊當(dāng)中,之所以說(shuō)是邏輯上連續(xù),是因?yàn)檎麄€(gè)內(nèi)存或者說(shuō)存儲(chǔ)器本身就是邏輯上連續(xù)的一個(gè)大內(nèi)存數(shù)組。如果我們用Java語(yǔ)言的類型來(lái)表示我們的存儲(chǔ)器的話,可以看做是byte[] memory這樣的類型。
數(shù)組的定義非常簡(jiǎn)單,它遵循以下這樣簡(jiǎn)單的規(guī)則。
T N[L];
這當(dāng)中T表示數(shù)據(jù)類型,N是變量名稱,L是數(shù)組長(zhǎng)度。這樣的聲明會(huì)做兩件事,首先是在內(nèi)存當(dāng)中開(kāi)辟一個(gè)長(zhǎng)為L(zhǎng)*length(T)的內(nèi)存空間(其中l(wèi)ength(T)是指數(shù)據(jù)類型的字節(jié)長(zhǎng)度),然后將這塊內(nèi)存空間的起始地址賦給變量N。當(dāng)我們使用N[index]去讀取數(shù)組元素的時(shí)候,我們會(huì)去讀N+index*length(T)的內(nèi)存位置,這一點(diǎn)并不難理解。
指針操作數(shù)組
在C語(yǔ)言當(dāng)中,*符號(hào)可以取一個(gè)指針指向的內(nèi)存區(qū)域的值,而對(duì)于數(shù)組來(lái)說(shuō),*符號(hào)依然可以這樣做。因此,我們可以很輕松地想到,對(duì)于上面的聲明來(lái)說(shuō),*N就相當(dāng)于N[0],類似的,*(N+1)就相當(dāng)于N[1],以此類推。
在上面*(N+1)這樣的方式當(dāng)中,我們其實(shí)對(duì)指針進(jìn)行了運(yùn)算,即對(duì)數(shù)組的起始地址N加了上1。在這一過(guò)程中,編譯器會(huì)幫我們自動(dòng)乘上數(shù)據(jù)類型的長(zhǎng)度(比如int為4),如此一來(lái),我們的指針運(yùn)算才算是正確了,比如對(duì)于*(N+1)來(lái)說(shuō),假設(shè)T為int類型,則 【實(shí)際地址(N+1)】 = N + 1 * 4。對(duì)于這一點(diǎn),我們可以用以下這個(gè)小程序來(lái)驗(yàn)證一下,從這個(gè)程序可以很明顯的看出來(lái),當(dāng)我們對(duì)指針進(jìn)行加1操作的時(shí)候,實(shí)際的地址會(huì)被乘以數(shù)據(jù)類型的長(zhǎng)度。
定長(zhǎng)和變長(zhǎng)數(shù)組
要理解定長(zhǎng)和變長(zhǎng)數(shù)組,我們必須搞清楚一個(gè)概念,就是說(shuō)這個(gè)“定”和“變”是針對(duì)什么來(lái)說(shuō)的。在這里我們說(shuō),這兩個(gè)字是針對(duì)編譯器來(lái)說(shuō)的,也就是說(shuō),如果在編譯時(shí)數(shù)組的長(zhǎng)度確定,我們就稱為定長(zhǎng)數(shù)組,反之則稱為變長(zhǎng)數(shù)組。
比如上圖當(dāng)中的示例,就是一個(gè)定長(zhǎng)數(shù)組,它的長(zhǎng)度為10,它的長(zhǎng)度在編譯時(shí)已經(jīng)確定了,因?yàn)殚L(zhǎng)度是一個(gè)常量。之前的C編譯器不允許在聲明數(shù)組時(shí),將長(zhǎng)度定義為一個(gè)變量,而只能是常量,不過(guò)當(dāng)前的C/C++編譯器已經(jīng)開(kāi)始支持動(dòng)態(tài)數(shù)組,但是C++的編譯器依然不支持方法參數(shù)。另外,C語(yǔ)言還提供了類似malloc和calloc這樣的函數(shù)動(dòng)態(tài)的分配內(nèi)存空間,我們可以將返回結(jié)果強(qiáng)轉(zhuǎn)為想要的數(shù)組類型。
接下來(lái),LZ和各位一起分析一個(gè)有關(guān)數(shù)組的C程序,我們先來(lái)一個(gè)簡(jiǎn)單的,也就是一個(gè)定長(zhǎng)數(shù)組,我們看下在匯編級(jí)別是如何操作定長(zhǎng)數(shù)組的。需要一提的是,由于數(shù)組的長(zhǎng)度固定,所以有的時(shí)候編譯器會(huì)根據(jù)實(shí)際情況作出一些優(yōu)化,以下是一個(gè)簡(jiǎn)單的小程序。
int main(){
int a[5];
int i,sum;
for(i = 0 ; i < 5; i++){
a[i] = i * 3;
}
for(i = 0 ; i < 5; i++){
sum += a[i];
}
return sum;
}以上這個(gè)小程序的功能LZ就不介紹了,如果哪位猿友看不懂,請(qǐng)自覺(jué)面壁吧。下面我們來(lái)看下-S和-O1下的匯編代碼,如下所示。
main:
pushl %ebp
movl %esp, %ebp//到此準(zhǔn)備好棧幀
subl $32, %esp//分配32個(gè)字節(jié)的空間
leal -20(%ebp), %edx//將幀指針減去20賦給%edx寄存器?為什么?你能猜到嗎?
movl $0, %eax//將%eax設(shè)置為0,這里的%eax寄存器是重點(diǎn)
.L2:
movl %eax, (%edx)//將0放入幀指針減去20的位置?
addl $3, %eax//第一次循環(huán)時(shí),%eax為3,對(duì)于i來(lái)說(shuō),%eax=(i+1)*3。
addl $4, %edx//將%edx加上4,第一次循環(huán)%edx指向幀指針-16的位置
cmpl $15, %eax//比較%eax和15?
jne .L2//如果不相等的話就回到L2
movl -20(%ebp), %eax//下面這五句指令已經(jīng)出賣了leal指令,很明顯從-20到-4,就是數(shù)組五個(gè)元素存放的地方。下面的就不解釋了,直接依次相加然后返回結(jié)果。
addl -16(%ebp), %eax
addl -12(%ebp), %eax
addl -8(%ebp), %eax
addl -4(%ebp), %eax
leave
retLZ這里就不再一個(gè)一個(gè)介紹這些指令的作用了,如果各位猿友是一路看過(guò)來(lái)的,這些指令其實(shí)難不倒各位。我們主要來(lái)看下跟數(shù)組相關(guān)的地方。上面其實(shí)并沒(méi)有完全解釋清楚數(shù)組的賦值操作那一部分,但是后面求和的部分卻已經(jīng)十分清楚了,現(xiàn)在LZ就幫各位串聯(lián)一下賦值的那部分。為了更加清晰,LZ廢話不多說(shuō),直接上圖。我們看下循環(huán)過(guò)程中是怎么計(jì)算的。
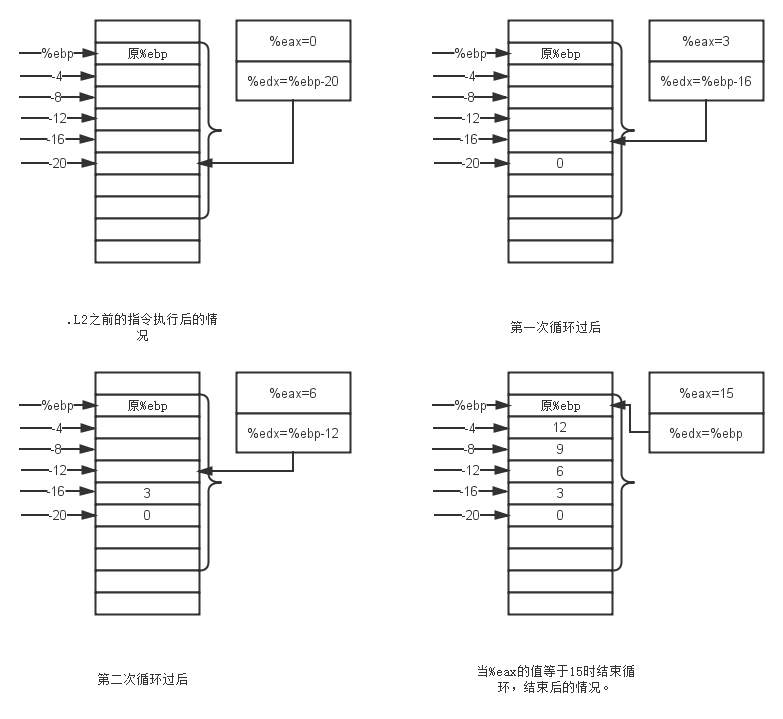
看了這個(gè)圖相信各位更加清楚程序的意圖了,開(kāi)始將%ebp減去20是為了依次給數(shù)組賦值。這里編譯器用了非常變態(tài)的優(yōu)化技巧,說(shuō)真的,LZ編譯之前也沒(méi)想到。那就是編譯器發(fā)現(xiàn)了a[i+1] = a[i] + 3的規(guī)律,因此使用加法(將%eax不斷加3)代替了i*3的乘法操作,另外也使用了加法(即地址不斷加4,而不使用起始地址加上索引乘以4的方式)代替了數(shù)組元素地址計(jì)算過(guò)程中的乘法操作。而循環(huán)條件當(dāng)中的i<5,也變成了3*i<15,而3*i又等于a[i],因此當(dāng)整個(gè)數(shù)組當(dāng)中循環(huán)的索引i,滿足a[i+1]=15(注意,在循環(huán)內(nèi)的時(shí)候,%eax一直儲(chǔ)存著a[i+1]的值,除了剛開(kāi)始的0)的時(shí)候,說(shuō)明循環(huán)該結(jié)束了,也就是coml和jne指令所做的事。
搞清楚了上面定長(zhǎng)數(shù)組的實(shí)現(xiàn),我們會(huì)發(fā)現(xiàn),定長(zhǎng)數(shù)組可以做很多的優(yōu)化,想象一下,如果上面的數(shù)組長(zhǎng)度是不定的,編譯器還能算出15這個(gè)數(shù)值嗎。接下來(lái)我們就來(lái)看一個(gè)和上面的代碼幾乎一模一樣的程序,只不過(guò)這里將換成變長(zhǎng)數(shù)組。
int sum(int n){
int a[n];
int i,sum;
for(i = 0 ; i < n; i++){
a[i] = i * 3;
}
for(i = 0 ; i < n; i++){
sum += a[i];
}
return sum;
}可以看到,我們改了一下函數(shù)名稱,并給函數(shù)加了個(gè)參數(shù)n并將a變?yōu)樽冮L(zhǎng)數(shù)組,其它沒(méi)做任何改動(dòng)。下面我們來(lái)看下-S和-O1下的匯編代碼,看看與定長(zhǎng)數(shù)組的差距在哪里。
.file "arr.c"
.text
.globl sum
.type sum, @function
sum:
pushl %ebp
movl %esp, %ebp
pushl %esi
pushl %ebx
subl $16, %esp
movl 8(%ebp), %ebx
movl %gs:20, %edx
movl %edx, -12(%ebp)
xorl %edx, %edx
leal 30(,%ebx,4), %edx
andl $-16, %edx
subl %edx, %esp
leal 15(%esp), %esi
andl $-16, %esi
testl %ebx, %ebx
jle .L2
movl $0, %ecx
movl $0, %edx
.L3:
movl %ecx, (%esi,%edx,4)
addl $1, %edx
addl $3, %ecx
cmpl %ebx, %edx
jne .L3
movl $0, %edx
.L4:
addl (%esi,%edx,4), %eax
addl $1, %edx
cmpl %ebx, %edx
jne .L4
.L2:
movl -12(%ebp), %edx
xorl %gs:20, %edx
je .L6
call __stack_chk_fail
.L6:
leal -8(%ebp), %esp
popl %ebx
popl %esi
popl %ebp
.p2align 4,,1
ret
.size sum, .-sum
.ident "GCC: (Ubuntu 4.4.3-4ubuntu5.1) 4.4.3"
.section .note.GNU-stack,"",@progbits或許個(gè)別猿友看到這一段匯編代碼會(huì)大吃遺精,因?yàn)樗雌饋?lái)比定長(zhǎng)數(shù)組要復(fù)雜太多,不管是長(zhǎng)度還是其中的指令。LZ猜測(cè),動(dòng)態(tài)數(shù)組的復(fù)雜性可能也是動(dòng)態(tài)數(shù)組出現(xiàn)較晚的原因,更何況動(dòng)態(tài)數(shù)組還有緩沖區(qū)溢出的危險(xiǎn)。
接下來(lái)LZ帶著各位猿友分步去看這一段匯編代碼,首先我們分析第一部分,包括了棧幀的建立、被調(diào)用者保存寄存器的備份以及棧內(nèi)存的分配。它包括了以下幾個(gè)開(kāi)頭的指令。
pushl %ebp
movl %esp, %ebp
pushl %esi
pushl %ebx
subl $16, %espLZ使用一幅圖來(lái)說(shuō)明這個(gè)問(wèn)題,我們來(lái)分別看看,在指令執(zhí)行前后,寄存器以及存儲(chǔ)器的狀態(tài)。
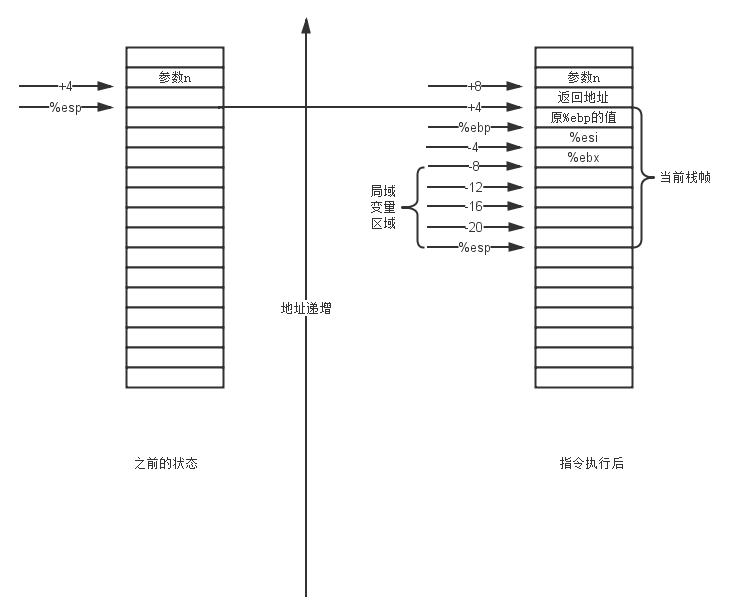
上面的這一過(guò)程是比較正常的棧幀建立過(guò)程,如果各位猿友看過(guò)過(guò)程實(shí)現(xiàn)那一章的話,那么上面這個(gè)過(guò)程并不復(fù)雜,因此LZ這里就不多說(shuō)廢話了,如果哪位猿友不清楚的話,可以去看看過(guò)程實(shí)現(xiàn)3.7的那一章。
接下來(lái),我們看看比較復(fù)雜的一段代碼,這一段代碼的主要目的,是為動(dòng)態(tài)數(shù)組分配內(nèi)存。它們是如下的這些指令
movl 8(%ebp), %ebx
movl %gs:20, %edx
movl %edx, -12(%ebp)
xorl %edx, %edx
leal 30(,%ebx,4), %edx
andl $-16, %edx
subl %edx, %esp
leal 15(%esp), %esi
andl $-16, %esi這一段代碼相對(duì)于上一段就復(fù)雜了一點(diǎn),接下來(lái)LZ還是先上一個(gè)指令執(zhí)行前后的圖,如下。

我們仔細(xì)對(duì)比一下左右兩張圖可以發(fā)現(xiàn),這里面最主要的兩個(gè)值,就存在%edx和%esi寄存器當(dāng)中。其中%edx的值是為數(shù)組分配的內(nèi)存字節(jié)數(shù),而%esi當(dāng)中存儲(chǔ)的則是數(shù)組的起始地址。我們不難想到,對(duì)于一個(gè)int類型長(zhǎng)度為n的數(shù)組,它占用的內(nèi)存字節(jié)數(shù)肯定是4n。而這里特別的地方就是,為什么不直接分配4n個(gè)字節(jié)然后把棧頂作為數(shù)組起始位置,而是分配了(30+4n)&(-16)的字節(jié),之后又把(%esp+15)&(-16)的位置作為數(shù)組的起始位置?
這個(gè)問(wèn)題的答案就是:為了效率。
為了提高內(nèi)存的讀取速度,一般都會(huì)將字節(jié)對(duì)齊,而針對(duì)棧內(nèi)存的分配,則大部分會(huì)保持為16字節(jié)的倍數(shù)。比如,如果處理器總是一次性從存儲(chǔ)器中讀取16個(gè)字節(jié),則地址必須為16的倍數(shù)才行,也就是說(shuō)地址的后4位必須為0。這樣的話我們就好理解了,因?yàn)闂僮魇菑臈m旈_(kāi)始,直到幀指針或者備份著被調(diào)用者寄存器的內(nèi)存位置為止(也就是上圖中局域變量區(qū)域的范圍),因此我們需要保證分配的字節(jié)數(shù)是16的倍數(shù)。
如此一來(lái),分配(30+4n)&(-16)個(gè)字節(jié),就可以保證上圖中-24的位置到%esp依然是16的倍數(shù)。因?yàn)閷?duì)于任意一個(gè)正整數(shù)i來(lái)講,都有i - 15 =< i&(-16) <= i,并且i&(-16)是16的倍數(shù)。因此對(duì)于(30+4n)&(-16)來(lái)說(shuō),就有以下結(jié)果。
4n + 15 =<(30+4n)&(-16) <= 4n + 30
這就保證了新分配的棧內(nèi)存大小既是16的倍數(shù),又能裝下n個(gè)整數(shù),因?yàn)樗笥?n。不過(guò)這里很明顯至少多了15個(gè)字節(jié),這15個(gè)字節(jié)會(huì)被數(shù)組的起始地址消除掉。從圖中可以看出,數(shù)組的起始地址并不是從棧頂開(kāi)始的(從%esi指向的位置開(kāi)始),這是因?yàn)閿?shù)組的起始地址等于(%esp+15)&(-16),而不是%esp。這樣做的目的也是為了對(duì)齊,只不過(guò)這里是地址對(duì)齊,將數(shù)組的起始地址對(duì)齊到16倍數(shù)的位置。由上面的結(jié)論我們知道。
%esp =<(%esp+15)&(-16) <= %esp + 15
上面的地址保證了數(shù)組的起始地址不會(huì)逃出棧頂,這也是%esp要加上15的原因。由于數(shù)組的起始地址可能上移15位,因此原本預(yù)留的空間將可能再次縮小15個(gè)字節(jié)(位于%esi和%esp之間的那一小段)。因此我們就能得出實(shí)際可用的空間stack有如下范圍。
4n <= stack <= 4n + 15
這下各位就明白了,為什么4n要加上30,而不是加上15。是因?yàn)閮纱闻c-16的“與”運(yùn)算,可能讓空間浪費(fèi)30個(gè)字節(jié)。所以加上30之后,就可以保證在滿足棧內(nèi)局部變量長(zhǎng)度和數(shù)組起始位置都為16的倍數(shù)的前提下,還能至少留出4n的空間供數(shù)組使用。
還有一點(diǎn)需要一提的是,上圖當(dāng)中還出現(xiàn)了一個(gè)“金絲雀值”,這個(gè)家伙是為了防止棧緩沖區(qū)溢出。這當(dāng)中的值是存儲(chǔ)器當(dāng)中的一個(gè)隨機(jī)值,倘若這個(gè)值在函數(shù)返回時(shí)改變了,那么就代表緩沖區(qū)溢出了,就會(huì)終止程序的運(yùn)行。
到此動(dòng)態(tài)數(shù)組占用的內(nèi)存區(qū)域就分配好了,接下來(lái)的就相對(duì)來(lái)說(shuō)比較簡(jiǎn)單了,基本上與定長(zhǎng)數(shù)組是一樣的。下面是接下來(lái)所有的匯編代碼,LZ直接加入了詳細(xì)的注釋,相信各位猿友不難看懂。
testl %ebx, %ebx//測(cè)試n是否大于0
jle .L2//如果n小于等于0,就跳過(guò)兩個(gè)循環(huán),跳到L2
movl $0, %ecx//%ecx與定長(zhǎng)數(shù)組中的%eax作用一樣,先初始化為0,后面逐漸+3賦給數(shù)組元素
movl $0, %edx//%edx就是i,這里是i=0
.L3:
movl %ecx, (%esi,%edx,4)//對(duì)于i=0的時(shí)候來(lái)說(shuō),這里則相當(dāng)于a[0]=0,因?yàn)?esi是數(shù)組起始地址。對(duì)于i來(lái)說(shuō),這里則代表a[i]=%ecx,a[i]的地址為a+4*i。
addl $1, %edx//i自增
addl $3, %ecx//將%eax加3,對(duì)于i=0的時(shí)候來(lái)說(shuō),%ecx就是a[1]的值。對(duì)于i來(lái)說(shuō),%ecx就是a[i+1]的值。
cmpl %ebx, %edx//比較n和i
jne .L3//如果i和n不相等則繼續(xù)循環(huán)。
movl $0, %edx//再次將i清0,即i=0
.L4:
addl (%esi,%edx,4), %eax//%eax就相當(dāng)于sum,這里其實(shí)就是sum = sum + a[i],其中a[i]的地址為a+4*i。
addl $1, %edx//i自增
cmpl %ebx, %edx//比較n和i
jne .L4//如果n和i不相等則繼續(xù)循環(huán)
.L2:
movl -12(%ebp), %edx//取出金絲雀值
xorl %gs:20, %edx//比較金絲雀值是否改變
je .L6//如果金絲雀值與原來(lái)的值相等,則代表緩沖區(qū)沒(méi)溢出,跳到L6繼續(xù)執(zhí)行。
call __stack_chk_fail//如果不相等,則代表緩沖區(qū)溢出,產(chǎn)生一個(gè)棧檢查錯(cuò)誤。
.L6:
leal -8(%ebp), %esp//讓棧頂指向備份的%ebx,回收內(nèi)存。
popl %ebx//還原備份的%ebx值
popl %esi//還原備份的%esi值
popl %ebp//恢復(fù)原來(lái)的幀指針
.p2align 4,,1//對(duì)齊地址為16的倍數(shù)
ret//函數(shù)返回上面的這些指令相對(duì)來(lái)講就比前面的簡(jiǎn)單了許多,相信各位猿友看注釋就能理解的八九不離十了,唯一特別一點(diǎn)的指令就是最后一個(gè)p2align指令。其實(shí)之前LZ也沒(méi)見(jiàn)過(guò)這個(gè)指令,但是從名字上也能大概看出來(lái)是干嘛的,不過(guò)最終LZ還是很快google到了這個(gè)指令的簡(jiǎn)單說(shuō)明。它會(huì)將地址對(duì)齊為16(也就是第一個(gè)參數(shù)4,表示2的4次方的意思)的倍數(shù),并最多跳過(guò)1個(gè)字節(jié)(也就是最后的參數(shù)1)。如果對(duì)齊需要跳過(guò)多于1個(gè)字節(jié),則會(huì)忽略這個(gè)指令。
異質(zhì)結(jié)構(gòu)與數(shù)據(jù)對(duì)齊
異質(zhì)結(jié)構(gòu)是指不同數(shù)據(jù)類型的數(shù)組組合,比如C語(yǔ)言當(dāng)中的結(jié)構(gòu)(struct)與聯(lián)合(union)。在理解數(shù)組的基礎(chǔ)上,這兩種數(shù)據(jù)結(jié)構(gòu)都非常好理解。我們先來(lái)看一個(gè)結(jié)構(gòu)的例子,比如下面的這個(gè)結(jié)構(gòu)。
#include <stdio.h>
struct {
int a;
int b;
char c;
} mystruct;
int main(){
printf("%d\n",sizeof mystruct);
}這是一個(gè)非常簡(jiǎn)單的結(jié)構(gòu)體,這個(gè)程序在LZ的32位windows系統(tǒng)上,輸出結(jié)果是12,或許有的猿友還可以得到10或者16這樣的結(jié)果。或許有的猿友會(huì)奇怪,為什么不是4+4+1=9呢。
這正是因?yàn)樯厦嫖覀兲岬竭^(guò)的對(duì)齊的原因,只不過(guò)這里的對(duì)齊不是地址對(duì)齊也不是棧分配空間對(duì)齊,而是數(shù)據(jù)對(duì)齊。為了提高數(shù)據(jù)讀取的速度,一般情況下會(huì)將數(shù)據(jù)以2的指數(shù)倍對(duì)齊,具體是2、4、8還是16,得根據(jù)具體的硬件設(shè)施以及操作系統(tǒng)來(lái)決定。
這樣做的好處是,處理器可以統(tǒng)一的一次性讀取4(也可能是其它數(shù)值)個(gè)字節(jié),而不再需要針對(duì)特殊的數(shù)據(jù)類型讀取做特殊處理。在這個(gè)例子來(lái)說(shuō),也就是說(shuō)在讀取a、b、c時(shí),都可以統(tǒng)一的讀取4個(gè)字節(jié)。特殊的,這里0-3的位置用于存儲(chǔ)a,4-7的位置用于存儲(chǔ)b,8的位置用于存儲(chǔ)c,而9-11則用于填充,其中都是空的。
與結(jié)構(gòu)體不同的是,聯(lián)合會(huì)復(fù)用內(nèi)存空間,以節(jié)省內(nèi)存,比如我們看下面這個(gè)例子。
#include <stdio.h>
union {
int a;
int b;
char c;
} myunion;
int main(){
printf("%d\n",sizeof myunion);
}這段程序輸出的結(jié)果是4,依舊是LZ的32位windows操作系統(tǒng)的結(jié)果。這是因?yàn)閍、b、c會(huì)共用4個(gè)字節(jié),這樣做的目的不言而喻,是為了節(jié)省內(nèi)存空間,顯然它比結(jié)構(gòu)體節(jié)省了8個(gè)字節(jié)的空間。它與結(jié)構(gòu)體最大的區(qū)別就在于,對(duì)a、b、c賦值時(shí),聯(lián)合會(huì)覆蓋掉之前的賦值,而結(jié)構(gòu)體則不會(huì),結(jié)構(gòu)體可以同時(shí)保存a、b、c的值。
對(duì)于結(jié)構(gòu)體和聯(lián)合,LZ這里就不再列舉具體的例子了,如果各位掌握了數(shù)組的匯編級(jí)操作,那么這兩個(gè)各位猿友完全可以私底下自己分析了。對(duì)于對(duì)齊來(lái)說(shuō),LZ還想多說(shuō)幾句。首先各位猿友要分清地址對(duì)齊、數(shù)據(jù)對(duì)齊和棧分配對(duì)齊的區(qū)別。另外一點(diǎn)就是地址對(duì)齊的大致規(guī)則,一般會(huì)依據(jù)數(shù)據(jù)類型的長(zhǎng)度來(lái)對(duì)齊(比如int為4位對(duì)齊,double為8位對(duì)齊等等),但最低為2。不過(guò)這些都不是絕對(duì)的,比如double也可能會(huì)依據(jù)4位對(duì)齊,因此具體的對(duì)齊規(guī)則還是需要根據(jù)硬件設(shè)施和操作系統(tǒng)決定。
最后一點(diǎn)需要各位明白的是,對(duì)齊是在拿空間換時(shí)間,也就是說(shuō),對(duì)齊浪費(fèi)了存儲(chǔ)空間,但提高了運(yùn)行速度。這有點(diǎn)類似于算法的時(shí)間復(fù)雜度和空間復(fù)雜度,兩者大部分情況下總是矛盾的。
淺談數(shù)組與指針
從上面的匯編分析來(lái)看,我們可以很輕松的得到一個(gè)結(jié)論,那就是數(shù)組變量其實(shí)就是數(shù)組的起始地址,就像動(dòng)態(tài)數(shù)組例子當(dāng)中的%esi寄存器一樣,它代表著數(shù)組a變量,同時(shí)也是數(shù)組的起始地址。而對(duì)于指針的運(yùn)算,在計(jì)算實(shí)際地址時(shí),會(huì)根據(jù)數(shù)據(jù)類型進(jìn)行伸縮,比如動(dòng)態(tài)數(shù)組一例中,每次在取數(shù)組元素時(shí),總有一個(gè)權(quán)重值是4(比如這個(gè)在上面出現(xiàn)過(guò)的內(nèi)存地址(%esi,%edx,4),它就是在讀取數(shù)組元素),這正是int類型的長(zhǎng)度。
以上就是本文的全部?jī)?nèi)容,希望對(duì)大家的學(xué)習(xí)有所幫助,也希望大家多多支持html5模板網(wǎng)。